
Python 汇总 Excel 多张工作表数据
看过来
《pandas 教程》 持续更新中,提供建议、纠错、催更等加作者微信: gr99123(备注:pandas教程)和关注公众号「盖若」ID: gairuo。跟作者学习,请进入 Python学习课程。欢迎关注作者出版的书籍:《深入浅出Pandas》 和 《Python之光》。

Python 在办公自动化方面近些年来大显身手,它在处理 Excel 中更是十分方便,促使了大量白领竞相学习的热潮。今天我们就来用 Python 中的 pandas 库完成一个日常中最简单的数据合并需求。
数据与需求
我们的原始数据是一个 Excel 表格,可以通过 这儿 进行下载,它的样子是:
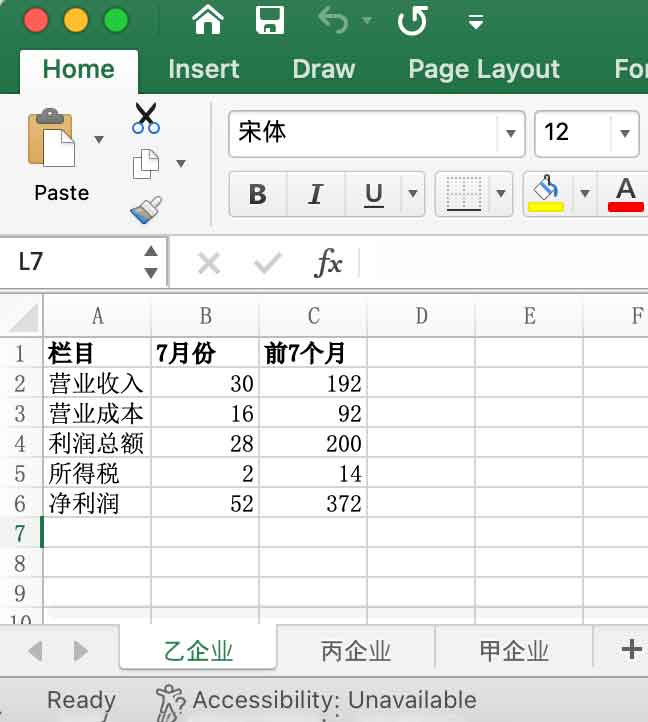
目前有三个工作簿(sheet),名称是企业的名称,每个 sheet 的结构一模一样。
本需求希望将这些个 Excel 所有工作簿(sheet)的对应数据相加,得到一个汇总的 Excel 文件。
思路
整体思路是让所有的 sheet 转为 DataFrame,然后直接相加,因为相同结构的 DataFrame 可以直接完成向量化的操作。
这个案例与 pandas 对 Excel 每个工作簿增加值为工作簿名称的列 类似,我们先需求将这个 Excel 的所有 sheet 读取出来。
代码
先读取 Excel,得到一个字典:
import pandas as pd
dfs = pd.read_excel('company.xlsx', sheet_name=None, index_col=0)
dfs
'''
{'乙企业': 栏目 7月份 前7个月
0 营业收入 30 192
1 营业成本 16 92
2 利润总额 28 200
3 所得税 2 14
4 净利润 52 372,
'丙企业': 栏目 7月份 前7个月
0 营业收入 23 106
1 营业成本 10 54
2 利润总额 13 52
3 所得税 2 9
4 净利润 11 43,
'甲企业': 栏目 7月份 前7个月
0 营业收入 15 96
1 营业成本 8 46
2 利润总额 7 50
3 所得税 1 7
4 净利润 6 43}
'''
以上代码 sheet_name=None 可获取所有 sheet 数据,返回的是一个字典,否则只读取第一个 sheet 返回一个 DataFrame。index_col=0 表示将所有表的第一个列设置为索引,会按索引对齐将操作,这列不进行合并相加计算,不设置为索引则会做相加操作。
然后用 Python 内置库的 reduce 完成有所有 DataFrame 的递归相加:
from functools import reduce
df = reduce(pd.DataFrame.add, dfs.values())
df
'''
7月份 前7个月
栏目
营业收入 68 394
营业成本 34 192
利润总额 48 302
所得税 5 30
净利润 69 458
'''
以上代码 reduce 是一个高阶函数,第一个参数操作函数,我们用的是 DataFrame 的 add 向量加法。第二个参数是一个要执行操作的序列(可迭代对象),由于 dfs 是一个字典,DataFrame 在值上,因此我们使用字典的 dict.values() 取得字典的值视图,它是一个可迭代对象,依次执行函数操作。
最后导出文件:
df.to_excel('汇总.xlsx', index=False)
# ... 可去当前文档下查看导出文件
这样就完成了需求。
(完)
相关内容
- pandas 案例 07 2024-08-18 16:15:45
- Python 基础使用案例 2021-11-10 00:00:05
- Python reduce() 聚合执行 2022-01-12 23:35:28
- pandas.read_excel() 详细介绍 2022-01-22 14:40:38
更新时间:2024-08-18 16:34:45 标签:pandas python excel 工作簿
