
《深入浅出Pandas》勘误及指导
公告
《深入浅出Pandas:利用Python进行数据处理与分析》已出版,各大电商平台均有销售。跟作者学习,请进入 Python学习课程。欢迎关注作者的相关书籍 《Python之光》。

本页整理书籍《深入浅出Pandas:利用Python进行数据处理与分析》的一些错误及修正内容,同时也会刊载一些阅读指导内容。欢迎指出错误(可进入系列首页找到作者联系方式联系作者),提供页码的错误的大致位置。
第1章
P13
注:此勘误2021年9月第2次印刷已经修正。
章节 1.2.10 中最后一行的: M / R:Markdown / 代码模式。 M / R 应为:M / Y。
P18
注:此勘误2022年8月第4次印刷已经修正。
章节 1.3.7 中 df.Q1 输出时应该索引的标签值应该为 name 的值。
第2章
P26
注:此勘误2021年9月第2次印刷已经修正。
章节 2.2 中:本节将讲述Python 的几大基础数字类型和结构。 数字类型 应为:数据类型
P29
注:此勘误2021年9月第2次印刷已经修正。
章节 2.2.3,本页第三行代码应该为:
a or b # 1 (a为假,返回b的值)
P31
注:此勘误暂未修正
章节 2.2.6 字典,常用的字典操作方法代码片断中相应的代码修改为:
d2 = d.copy() # 浅拷贝, d2变化不影响d1
P33
注:此勘误暂未修正
章节 2.3.2 中图 2-2 少两个方括号,在 10-18 最外侧,19 最外侧。
P35
注:此勘误2022年8月第4次印刷已经修正。
章节 2.3.5 数组信息中,第一行代码应该为:
n.shape # 数组的形状, 返回值是一个元组
第3章
P55
注:此勘误2022年8月第4次印刷已经修正。
章节 3.2.7,本页第一行代码的注释应该是:
# 以下用 callable 方式迭代列名,为 True 的被使用
pd.read_csv(data, usecols=lambda x: x.upper() in ['COL3', 'COL1'])
P56
注:此勘误2022年8月第4次印刷已经修正。
章节3.2.15 中代码的注释原为跳过前 3 行,应该是:
# 跳过前2行
pd.read_csv(data, skiprows=2)
# 跳过前2行
pd.read_csv(data, skiprows=range(2))
P59
注:此为指导阅读
章节 3.2.20 中 chunksize 参数的示例可替换为更加优雅的写法:
with pd.read_csv("tmp.sv", sep="|", chunksize=4) as reader:
for chunk in reader:
print(chunk)
第4章
P72
注:此勘误2021年9月第2次印刷已经修正。
章节 4.1.8 索引重命名的代码片断中,相关代码注释应为:
df.rename_axis('info', axis='columns') # 修改列索引名
# 修改多层行索引名
df.rename_axis(index={'a': 'A', 'b': 'B'})
P75
注:此勘误2021年9月第2次印刷已经修正。
章节 4.2.5 第一句描述中,df.axes 返回的列表形式为: [行索引, 列索引]。
2 )
注:此勘误暂未修正
章节 4.2.6 最后一段中,「s.name 可获取索引的名称」应该是: s.name 可获取 Series 的名称。
P82
注:此勘误2021年9月第2次印刷已经修正。
章节 4.4.3 中、4.4.4 小结前 first 参数和 dense 参数的介绍应该为:
- first:如并列第1名,按照索引的先后显示。
- dense:如并列第1名,则都显示1,下个数据为2。
P86
注:此为导读
loc、iloc、at、iat 支持索引、索引列表、切片,详见 pandas 函数详细介绍 中的专门介绍。
第5章
P91
注:此勘误2022年8月第4次印刷已经修正。
章节 5.1.2 中: 以下是.loc[] 和.lic[] 的一些示例: 应为: 以下是.loc[]的一些示例:。
注:此勘误2022年8月第4次印刷已经修正。
其下代码片断中第一行和最后一行代码互换(注释不变):
df.loc[df['Q1'] > 90, 'Q1'] # ...
...
df.loc[df['Q1'] > 90, 'Q1':] # ...
P95
注:此勘误2021年9月第2次印刷已经修正。
章节 5.2.2 指定类型第一个代码片断中应该为:
s = pd.to_numeric(m) # 转成数字
注:此为阅读指导
另注:pd.to_numeric 转换的数据如果为 Series 则返回 Series,如果为 其他的则返回 ndarray,因此 pd.to_numeric(m errors='coerce').fillna(0) 操作时需要先将 m 转为 Series 才能使用 fillna 方法。
P111
注:此勘误2021年9月第2次印刷已经修正。
章节 5.4.12 删除空值的代码片断中倒数第二行,相关注释应为:
df.dropna(thresh=2, axis=0) # 不足两个非空值时删除
第6章
P139
注:此勘误暂未修正
章节 6.3.3 的第一部分代码中,最后的输出结果前,应该增加一行代码:
grouped.Q1.sum()
P143
注:此勘误2022年8月第4次印刷已经修正。
章节 6.3.6 章节,本页第二个代码块中第三行代码,应该修正为:
# 使用函数, 和上一个学生的差值(没有处理姓名列)
df.groupby('team').transform(lambda x: x.diff(1))
第7章
P161
注:此勘误2022年8月第4次印刷已经修正。
章节 7.1.3 第一个代码片断中的 df3 展示有误,以实际执行结果为准。
P169
注:此勘误2021年9月第2次印刷已经修正。
章节 7.3.2 中的最后一行代码 pd.merge(df1, df2, on='a') 的返回结果应为:
pd.merge(df1, df2, on='a')
'''
a x y
0 1 5 7
1 2 6 6
'''
P173
注:此勘误2021年9月第2次印刷已经修正。
章节 7.4.3 df.update() 最后一句: 如果不想让df1 被更新,可以传入参数overwrite=True。 应为:overwrite=False。
P188
注:此勘误2021年9月第2次印刷已经修正。
章节 9.1.1 中的 图 9-1 df.pivot() 逻辑图示右侧的结果数据应为:
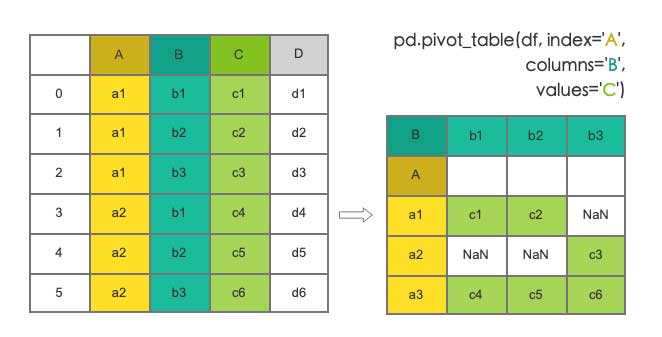
相关代码过程:
df = pd.DataFrame({
'A':['a1', 'a1', 'a2', 'a3', 'a3', 'a3'],
'B':['b1', 'b2', 'b3', 'b1', 'b2', 'b3'],
'C':['c1', 'c2', 'c3', 'c4', 'c5', 'c6'],
'D':['d1', 'd2', 'd3', 'd4', 'd5', 'd6'],
})
# 图示中的正确结果
df.pivot(index='A', columns='B', values='C')
'''
B b1 b2 b3
A
a1 c1 c2 NaN
a2 NaN NaN c3
a3 c4 c5 c6
'''
第11章
P237
注:此为阅读指导
章节 11.2.5 格式判定中的代码块中的所有方法都应该有小括号,因为它们全是方法,返回的是布尔值。
第16章
P337
注:此为阅读指导
章节 16.1.14 图形叠加的方法,随着后期版本的迭代可能无法实现,可以尝试以下方法:
ax = df['Q1'].head().plot.bar(),
ax = df.mean(1, numeric_only=True).head().plot(color='r')
以上方法在 Jupyterlab 上通过。
第17章
P376
注:此为阅读指导
章节 17.2.6 编写年会抽奖程序由于代码陈旧,不建议再学习,可浏览作者用类的方法编写的新代码,详见:用类编写一个年会抽奖程序 。
P379
注:此勘误2021年9月第2次印刷已经修正。
生成insert SQL 语句的代码中,值部分那里少右括号。应为:
sql = ''
for i,r in df.iterrows():
r_sql = f"INSERT INTO `holiday` (`holiday`, `year`, `start_date`, `end_date`)
VALUES ('{r['节日']}', '{r['结束日期'][:4]}', '{r['开始日期']}', '{r['结束日期']}');"
sql = sql + r_sql + '\n'
print(sql)
'''
INSERT INTO `holiday` (`holiday`, `year`, `start_date`, `end_date`) VALUES
('元旦', '2020', '2020-01-01', '2020-01-01');
INSERT INTO `holiday` (`holiday`, `year`, `start_date`, `end_date`) VALUES
('除夕', '2020', '2020-01-24', '2020-01-24');
INSERT INTO `holiday` (`holiday`, `year`, `start_date`, `end_date`) VALUES
('清明节', '2020', '2020-04-04', '2020-04-04');
INSERT INTO `holiday` (`holiday`, `year`, `start_date`, `end_date`) VALUES
('劳动节', '2020', '2020-05-01', '2020-05-01');
INSERT INTO `holiday` (`holiday`, `year`, `start_date`, `end_date`) VALUES
('端午节', '2020', '2020-06-25', '2020-06-25');
INSERT INTO `holiday` (`holiday`, `year`, `start_date`, `end_date`) VALUES
('国庆节', '2020', '2020-10-01', '2020-10-01');
'''
P403
注:此为阅读指导
指导信息:17.3.6 关于 RFM 模型的问题,如果使用了最新的 pandas 版本,在 P403 第一、二段代码执行时可能会遇到以下错误:
TypeError: Invalid comparison between dtype=category and float64
这是因为无法执行分类数据 category 与 float 类型对比操作导致的,可以在 r_e、f_e、m_e 列的指定代码中增加 astype(int) 将其转换为整型,再进行对比,如:
(
pd.DataFrame({'r': r,'f': f,})
# m为总金额/购买次数
.assign(m=lambda x: df.groupby(['用户']).sum()['金额']/x.f)
.assign(r_s=lambda x: pd.qcut(x.r, q=3, labels=[3,2,1]))
.assign(f_s=lambda x: pd.cut(x.f,bins=[0,2,5,float('inf')], labels=[1,2,3], right = False))
.assign(m_s=lambda x: pd.cut(x.m,bins=[0,30,60,float('inf')], labels=[1,2,3], right = False))
.assign(r_e=lambda x: (x.r_s.astype(int) > x.r_s.astype(int).mean())*1) # <--- ! 这儿
.assign(f_e=lambda x: (x.f_s.astype(int) > x.f_s.astype(int).mean())*1) # <--- ! 这儿
.assign(m_e=lambda x: (x.m_s.astype(int) > x.m_s.astype(int).mean())*1) # <--- ! 这儿
)
P404
注:此勘误暂未修正
章节 17.3.7 发送邮件代码中,Message 误写为 sysy,正确的代码为:
message = Message(subject='Congrats on the new job!', # 邮件主题
...
更新时间:2024-02-26 21:01:22 标签:pandas 勘误
