
数据湖
说明
数据产品经理教程 正在编写中,欢迎大家加微信 gr99123 (备注:数据产品教程) 提供意见、建议、纠错、催更。应大家要求,作者开办数据产品和数据分析培训班,详情 数据产品经理培训 / 数据分析培训。
数据湖(英语:data Lake),是指使用大型二进制对象或文件这样的自然格式储存数据的系统。它通常把所有的企业数据统一存储,既包括源系统中的原始副本,也包括转换后的数据,比如那些用于报表, 可视化, 数据分析和机器学习的数据。数据湖可以包括关系数据库的结构化数据(行与列)、半结构化的数据(CSV,日志,XML, JSON),非结构化数据 (电子邮件、文件、PDF)和 二进制数据(图像、音频、视频)。
储存数据湖的方式包括 Apache Hadoop 分布式文件系统, Azure 数据湖 或 亚马逊云 Lake Formation's云存储服务,以及诸如 Alluxio 虚拟数据湖之类的解决方案。
一个 数据沼泽 是一个劣化的数据湖,用户无法访问,或是没什么价值。
背景
据称此术语由James Dixon为了与数据集市对比而提出,当时他是Pentaho的首席技术官。 数据集市相对较小,包含从原始数据提取出来的有价值的属性。 在推广数据湖的时候,他认为,数据集市有几个固有的问题,例如 信息孤岛. 普华永道称,数据湖可以"解决数据孤岛。" 在其数据湖研究中,他们指出,企业"开始使用一个单一的、基于Hadoop的存储库来存放和提取数据。" Hortonworks, 谷歌, Oracle, Microsoft, Zaloni, 天睿动力的技术, Cloudera和 亚马逊 都有数据湖的产品。
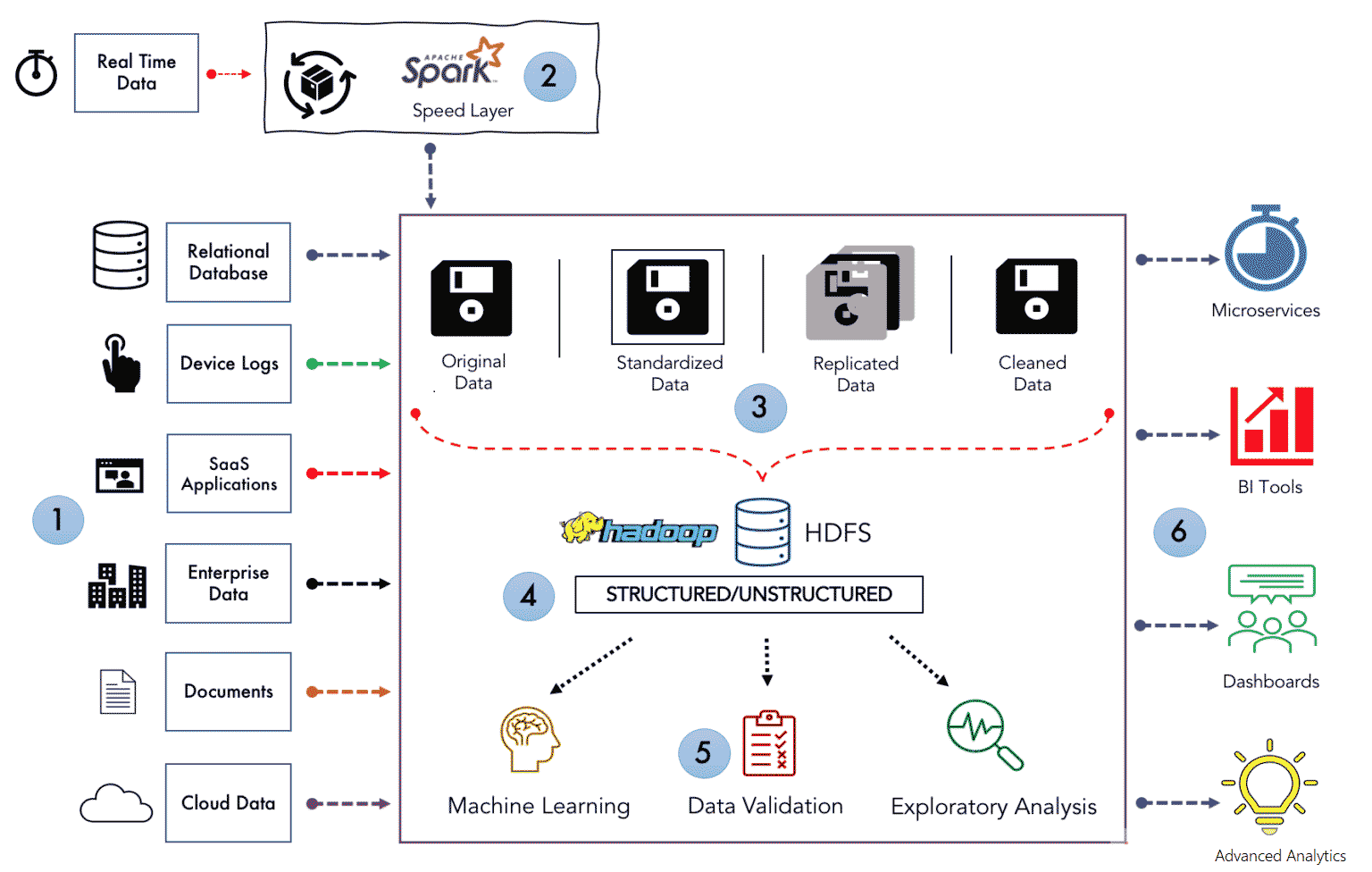
从数据采集到提供数据服务的流程:

发展
与数据湖不同,数据仓库是针对OLAP需求建设的数据库,可以分析来自交易系统或不同业务部门的结构化数据。数据仓库中的数据由原始数据经过清理、填充和转换后按照核心业务逻辑组织生成。数据仓库一般必须预先定义好数据库Schema,重点是实现更快的SQL驱动的深度报告和分析。
数据湖的出现主要是为了解决存储全域原始数据的问题。在捕获来自业务应用程序、移动应用程序、IoT设备和互联网的结构化和非结构化数据时,实际上并没有预先定义好数据结构,这意味着可以先存储数据而无须进行精心设计,也无须明确要进行什么分析,由数据科学家和数据工程师在后续工作中探索和尝试。
这个改动极大推动了大数据的发展,早期大数据系统的一大吸引力是能够存储大量日志数据供后期探索,很多大数据应用就是在大数据系统将数据采集上来之后才出现的。为什么一定要单独建立数据湖呢?要回答这个问题,我们先来了解数据湖的一个重要组成部分——ODS(Operating Data Store,运营数据存储)。在20世纪90年代数据仓库刚出来的时候,就已经有ODS了。可以说ODS是数据湖的先行者,因为ODS和数据湖有两个共同的重要特征:不加转换的原始数据,可以进行不预先设置的分析。
ODS一般用来存储业务运营数据,也就是OLTP(联机事务处理)数据的快照和历史,而数据仓库一般用来存储分析数据,对应OLAP(联机分析处理)需求。可了解:OLTP和OLAP。

绝大多数情况下,业务数据库的SQL库表的结构与数据仓库的结构是不一样的:业务数据库是为OLTP设计的,是系统实时状态的数据;而数据仓库的数据是为OLAP的需求建设的,是为了深度的多维度分析。这个差异造成基于数据仓库的数据分析受到以下限制:
数据仓库的架构设计是事先定好的,很难做到全面覆盖,因此基于数据仓库的分析是受到事先定义的分析目标及数据库Schema限制的;
从OLTP的实时状态到OLAP的分析数据的转换中会有不少信息损失,例如某个账户在某个具体时间点的余额,在OLTP系统里一般只存储最新的值,在OLAP系统里只会存储对账户操作的交易,一般不会专门存储历史余额,这就使得进行基于历史余额的分析非常困难。
因此,在建立数据仓库的时候,我们必须先将OLTP数据导入ODS,然后在ODS上进行ETL操作,生成便于分析的数据,最后将其导入数据仓库。这也是为什么ODS有时也被称为数据准备区(staging area)。
随着Hadoop的逐渐普及,大家发现数据仓库底层的技术(关系型数据库)无法处理一些非结构化数据,最典型的就是服务器日志包含的数据。除了这些分析上的功能缺陷之外,传统数据仓库底层使用的关系型数据库在处理能力上有很大局限,这也是数据湖,直至整个大数据生态出现的一个主要原因。
在Hadoop出现之前,就有Teradata和Vertica等公司试图使用MPP(Massively Parallel Processing,大规模并行处理)数据库技术来解决数据仓库的性能问题。在Hadoop出现之后,Hive成为一个比较廉价的数据仓库实现方式,也出现了Presto、Impala这些SQL-on-Hadoop的开源MPP系统。
从2010年开始,业界逐渐将ODS、采集的日志以及其他存放在Hadoop上的非结构或半结构化数据统称为数据湖。有时,数据湖中直接存储源数据副本的部分(包括ODS和日志存储)被称为贴源数据层,意思是原始数据的最直接副本。
从根本上来讲,数据湖的最主要目标是尽可能保持业务的可还原度。例如,在处理业务交易的时候,数据湖不仅会把OLTP业务数据库的交易记录采集到数据湖中的ODS,也会把产生这笔交易的相关服务器日志采集到数据湖的HDFS文件系统中,有时还会把发回给客户的交易凭证作为文档数据存放。
这样,在分析与这笔交易相关的信息时,系统能够知道这笔交易产生的渠道(从服务器分析出来的访问路径),给客户的凭证是否有不合理的数据格式(因为凭证的格式很多时候是可以动态变化的)。
功能
关于数据湖的定义其实很多,但是基本上都围绕着以下几个特性展开。
- 数据湖需要提供足够用的数据存储能力,这个存储保存了一个企业/组织中的所有数据。
- 数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
- 数据湖中的数据是原始数据,是业务数据的完整副本。数据湖中的数据保持了他们在业务系统中原来的样子。
- 数据湖需要具备完善的数据管理能力(完善的元数据),可以管理各类数据相关的要素,包括数据源、数据格式、连接信息、数据schema、权限管理等。
- 数据湖需要具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习;同时,还需要提供一定的任务调度和管理能力。
- 数据湖需要具备完善的数据生命周期管理能力。不光需要存储原始数据,还需要能够保存各类分析处理的中间结果,并完整的记录数据的分析处理过程,能帮助用户完整详细追溯任意一条数据的产生过程。
- 数据湖需要具备完善的数据获取和数据发布能力。数据湖需要能支撑各种各样的数据源,并能从相关的数据源中获取全量/增量数据;然后规范存储。数据湖能将数据分析处理的结果推送到合适的存储引擎中,满足不同的应用访问需求。
- 对于大数据的支持,包括超大规模存储以及可扩展的大规模数据处理能力。
数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。
特点
对数据湖的概念有了基本的认知之后,我们需要进一步明确数据湖需要具备哪些基本特征,特别是与大数据平台或者传统数据仓库相比,数据湖具有哪些特点。
保真性
数据湖中对于业务系统中的数据都会存储一份“一模一样”的完整拷贝。与数据仓库不同的地方在于,数据湖中必须要保存一份原始数据,无论是数据格式、数据模式、数据内容都不应该被修改。在这方面,数据湖强调的是对于业务数据“原汁原味”的保存。同时,数据湖应该能够存储任意类型/格式的数据。
灵活性
上表一个点是 “写入型Schema” v.s.“读取型Schema”,其实本质上来讲是数据Schema的设计发生在哪个阶段的问题。对于任何数据应用来说,其实Schema的设计都是必不可少的,即使是MongoDB等一些强调“无模式”的数据库,其最佳实践里依然建议记录尽量采用相同/相似的结构。
“写入型Schema”背后隐含的逻辑是数据在写入之前,就需要根据业务的访问方式确定数据的Schema,然后按照既定Schema,完成数据导入,带来的好处是数据与业务的良好适配;但是这也意味着数仓的前期拥有成本会比较高,特别是当业务模式不清晰、业务还处于探索阶段时,数仓的灵活性不够。
数据湖强调的“读取型Schema”,背后的潜在逻辑则是认为业务的不确定性是常态:我们无法预期业务的变化,那么我们就保持一定的灵活性,将设计去延后,让整个基础设施具备使数据“按需”贴合业务的能力。因此,个人认为“保真性”和“灵活性”是一脉相承的:既然没办法预估业务的变化,那么索性保持数据最为原始的状态,一旦需要时,可以根据需求对数据进行加工处理。
因此,数据湖更加适合创新型企业、业务高速变化发展的企业。同时,数据湖的用户也相应的要求更高,数据科学家、业务分析师(配合一定的可视化工具)是数据湖的目标客户。
可管理
数据湖应该提供完善的数据管理能力。既然数据要求“保真性”和“灵活性”,那么至少数据湖中会存在两类数据:原始数据和处理后的数据。数据湖中的数据会不断的积累、演化。因此,对于数据管理能力也会要求很高,至少应该包含以下数据管理能力:数据源、数据连接、数据格式、数据Schema(库/表/列/行)。同时,数据湖是单个企业/组织中统一的数据存放场所,因此,还需要具有一定的权限管理能力。
可追溯
数据湖是一个组织/企业中全量数据的存储场所,需要对数据的全生命周期进行管理,包括数据的定义、接入、存储、处理、分析、应用的全过程。一个强大的数据湖实现,需要能做到对其间的任意一条数据的接入、存储、处理、消费过程是可追溯的,能够清楚的重现数据完整的产生过程和流动过程。
在计算方面,个人认为数据湖对于计算能力要求其实非常广泛,完全取决于业务对于计算的要求。
丰富的计算引擎
从批处理、流式计算、交互式分析到机器学习,各类计算引擎都属于数据湖应该囊括的范畴。一般情况下,数据的加载、转换、处理会使用批处理计算引擎;需要实时计算的部分,会使用流式计算引擎;对于一些探索式的分析场景,可能又需要引入交互式分析引擎。
随着大数据技术与人工智能技术的结合越来越紧密,各类机器学习/深度学习算法也被不断引入,例如TensorFlow/PyTorch框架已经支持从HDFS/S3/OSS上读取样本数据进行训练。因此,对于一个合格的数据湖项目而言,计算引擎的可扩展/可插拔,应该是一类基础能力。
多模态的存储引擎
理论上,数据湖本身应该内置多模态的存储引擎,以满足不同的应用对于数据访问需求(综合考虑响应时间/并发/访问频次/成本等因素)。
但是,在实际的使用过程中,数据湖中的数据通常并不会被高频次的访问,而且相关的应用也多在进行探索式的数据应用,为了达到可接受的性价比,数据湖建设通常会选择相对便宜的存储引擎(如S3/OSS/HDFS/OBS),并且在需要时与外置存储引擎协同工作,满足多样化的应用需求。
数据湖建设目标
数据湖的建设方式有很多种,有的企业使用以Hadoop为核心的数据湖实现,有的企业以MPP为核心加上一些对象存储来实现。虽然建设方式不同,但是它们建设数据湖的目标是一致的,主要有以下4点。
- 高效采集和存储尽可能多的数据。将尽可能多的有用数据存放在数据湖中,为后续的数据分析和业务迭代做准备。一般来说,这里的“有用数据”就是指能够提高业务还原度的数据。
- 对数据仓库的支持。数据湖可以看作数据仓库的主要数据来源。业务用户需要高性能的数据湖来对PB级数据运行复杂的SQL查询,以返回复杂的分析输出。
- 数据探索、发现和共享。允许高效、自由、基于数据湖的数据探索、发现和共享。在很多情况下,数据工程师和数据分析师需要运行SQL查询来分析海量数据湖数据。诸如Hive、Presto、Impala之类的工具使用数据目录来构建友好的SQL逻辑架构,以查询存储在选定格式文件中的基础数据。这允许直接在数据文件中查询结构化和非结构化数据。
- 机器学习。数据科学家通常需要对庞大的数据集运行机器学习算法以进行预测。数据湖提供对企业范围数据的访问,以便于用户通过探索和挖掘数据来获取业务洞见。
基于这几个目标,数据湖必须支持以下特性。
- 数据源的全面性:数据湖应该能够从任何来源高速、高效地收集数据,帮助执行完整而深入的数据分析。
- 数据可访问性:以安全授权的方式支持组织/部门范围内的数据访问,包括数据专业人员和企业等的访问,而不受IT部门的束缚。
- 数据及时性和正确性:数据很重要,但前提是及时接收正确的数据。所有用户都有一个有效的时间窗口,在此期间正确的信息会影响他们的决策。
- 工具的多样性:借助组织范围的数据,数据湖应使用户能够使用所需的工具集构建其报告和模型。
数据湖数据的采集和存储
数据采集系统负责将原始数据从源头采集到数据湖中。数据湖中主要采集如下数据。
ODS
存储来自各业务系统(生产系统)的原始数据,一般以定时快照的方式从生产数据库中采集,或者采用变化数据捕获(Change Data Capture,CDC)的方式从数据库日志中采集。
后者稍微复杂一些,但是可以减少数据库服务器的负载,达到更好的实时性。在从生产数据库中采集的时候,建议设置主从集群并从从库中采集,以避免造成对生产数据库的性能影响。
服务器日志
系统中各个服务器产生的各种事件日志。典型例子是互联网服务器的日志,其中包含页面请求的历史记录,如客户端IP地址、请求日期/ 时间、请求的网页、HTTP代码、提供的字节数、用户代理、引用地址等。
这些数据可能都在一个文件中,也可能分隔成不同的日志,如访问日志、错误日志、引荐者日志等。我们通常会将各个业务应用的日志不加改动地采集到数据湖中。
动态数据
有些动态产生的数据不在业务系统中,例如为客户动态产生的推荐产品、客户行为的埋点数据等。这些数据有时在服务器日志中,但更多的时候要以独立的数据表或Web Service的方式进行采集。
埋点是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程,比如用户点击某个图标的次数、观看某个视频的时长等。
埋点是用户行为分析中非常重要的环节,决定了数据的广度、深度、质量,能影响后续所有的环节。因此,这部分埋点数据应该采集到数据湖中。
第三方数据
从第三方获得的数据,例如用户的征信数据、广告投放的用户行为数据、应用商店的下载数据等。
原始数据采集
采集这些原始数据的常见方式如下。
- 传统数据库数据采集:数据库采集是通过Sqoop或DataX等采集工具,将数据库中的数据上传到Hadoop的分布式文件系统中,并创建对应的Hive表的过程。数据库采集分为全量采集和增量采集,全量采集是一次性将某个源表中的数据全部采集过来,增量采集是定时从源表中采集新数据。
- Kafka实时数据采集:Web服务的数据常常会写入Kafka,通过Kafka快速高效地传输到Hadoop中。由Confluent开源的Kafka Connect架构能很方便地支持将Kafka中的数据传输到Hive表中。
- 日志文件采集:对于日志文件,通常会采用Flume或Logstash来采集。
- 爬虫程序采集:很多网页数据需要编写爬虫程序模拟登录并进行页面分析来获取。
- Web Service数据采集:有的数据提供商会提供基于HTTP的数据接口,用户需要编写程序来访问这些接口以持续获取数据。
数据湖存储
数据湖需要支持海量异构数据的存储。下面是一些常见的存储系统及其适用的数据类型。
- HDFS:一般用来存储日志数据和作为通用文件系统。
- Hive:一般用来存储ODS和导入的关系型数据。
- 键-值存储(Key-value Store):例如Cassandra、HBase、ClickHouse等,适合对性能和可扩展性有要求的加载和查询场景,如物联网、用户推荐和个性化引擎等。
- 文档数据库(Document Store):例如MongoDB、Couchbase等,适合对数据存储有扩展性要求的场景,如处理游戏账号、票务及实时天气警报等。
- 图数据库(Graph Store):例如Neo4j、JanusGraph等,用于在处理大型数据集时建立数据关系并提供快速查询,如进行相关商品的推荐和促销,建立社交图谱以增强内容个性化等。
- 对象存储(Object Store):例如Ceph、Amazon S3等,适合更新变动较少的对象文件数据、没有目录结构的文件和不能直接打开或修改的文件,如图片存储、视频存储等。
参考
- https://en.wikipedia.org/wiki/Data_lake
- https://mp.weixin.qq.com/s/6VktRyQB3XxcgM_ThkiCaw
- https://mp.weixin.qq.com/s/yh_pjyyzMZQd52WkiYZygA
更新时间:2022-07-11 16:54:51 标签:数据湖 大数据
