
ETL 是什么?
说明
数据产品经理教程 正在编写中,欢迎大家加微信 gr99123 (备注:数据产品教程) 提供意见、建议、纠错、催更。应大家要求,作者开办数据产品和数据分析培训班,详情 数据产品经理培训 / 数据分析培训。
ETL,全称 Extract-Transform-Load,它是将大量的原始数据经过提取(extract)、转换(transform)、加载(load)到目标存储数据仓库的过程。ETL 虽然大部分应用在大数据领域,对小数据也可以经过这个过程的处理。
理解 ETL
ETL 是企业数据应用过程中的一个数据流(pipeline)的控制技术,把原始的数据经过一定的处理,放入数据仓库里。
可以想象一下一条大河的源头被污染,下游就无法作为饮用水源,也无法用于灌溉。如果想用于灌溉,就要将河上游工厂的污水进行处理之后再排入,如果想用于饮用,那就要用水淡化或者渗透过滤技术,对水质进行改造。
同样,原始数据并不是完美的、洁净的,质量参差不齐的数据对于数据最终的使用会产生很大的影响。
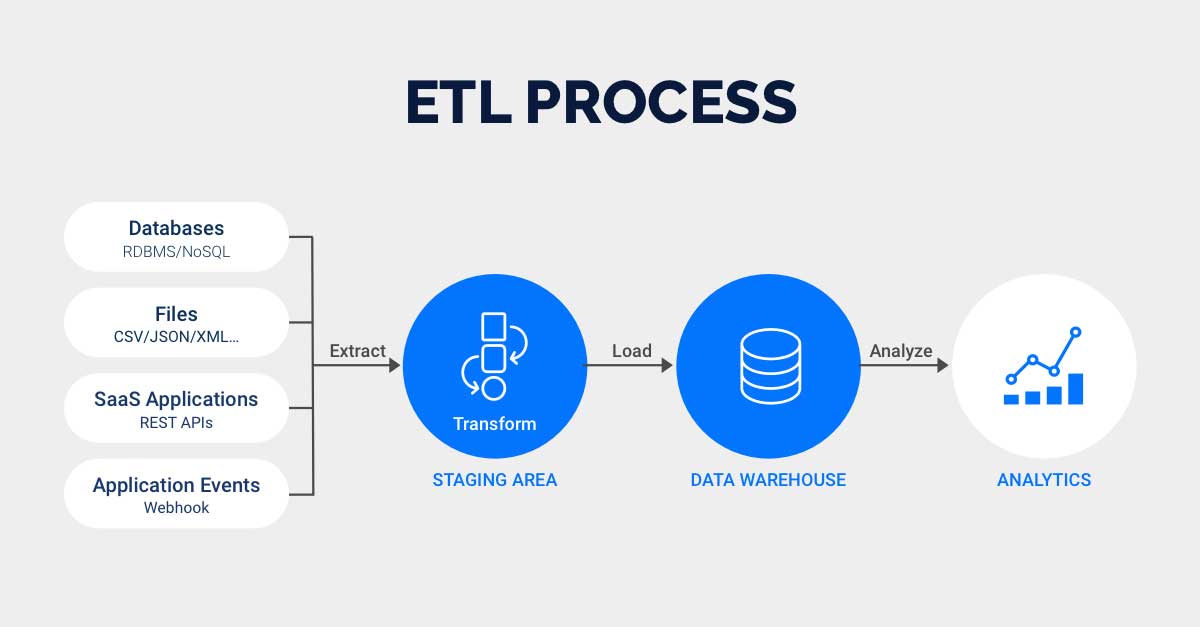
除了数据的清洗,还要将所有有用的数据汇集在一起,ETL 就是这样可以重复的,有周期性的一个过程。
提取 extract
在提取阶段,解决的是数据来源问题。主要有以下几种:
业务数据
在我们企业运行过程中,会有一些用户的交易数据,如用户的购买订单、退款退货、用户发布的视频、用户的注册信息等等,这些都存在我们的业务数据库里,这些数据库通常是关系型数据库,这是我们获取数据的一个重要来源。文件数据
还有一些数据是有文件的形式存在,比如我们服务器运行的 log,它记录了用户对网站的请求情况,再比如我们通过埋点收集的日志文件,记录了用户的交互。第三方数据
通过第三方购买或者合作形式信用的数据,这些数据可以作为我们业务分析的补充数据。这些数据一般通过和第三方机构的接口(API)形式,对接传输过来。三方的来源、数据形式格式可能有多种多样,就需要我们分别进行对接处理。
数据的格式和形式一般有以下几种:
- 关系型数据库 SQL,RDBMS
- 文件型数据库 NoSQL
- 日志文件
- XML/Html
- JSON
- CSV/TSV(flat files)
- 等等
Staging Area 为缓存区,在数据加载后进行处理时,将过程中的结果暂时存放起来,有些计算需要一定的硬件资源和时间,设定缓冲区可以对 ETL 有很大有帮助。
提取是把多种多样的原格式数据抽象出来,形成统一的数据格式先放入缓存区,不会直接进入数据仓库,等待下一步转换操作。
转换 transform
弄清楚了数据来源,前边做了数据的整合,对文件格式进行了一些处理。本步骤,根据我们的商业需要,我们用一些规则、方法进行数据处理。一般常见的转换操作有:
- 筛选:筛选部分数据,或者部分字段,提取一部分有用的数据
- 清理:缺失值填充、默认值设定、枚举映射等,如将一些编码转为可识别的符号,比如省份代码 sh 转为「上海」
- 合并:将多个属性合并在一起
- 格式转换:,如原数据是一下个时间戳(timestamp),我们为了方便后续分析转换为时间格式,指定时区
- 拆分:将单个属性值拆分为多个属性值,如原为一个邮编,拆分解析成省份、城市等多个字段
- 排序:按期望的数据顺序进行排列
- 计算:如原数据为年龄,用当前年份减去年龄同,取得出生年份
原则:
- 建数仓时尽量保留原始数据,支持多样需求
- 为特定报表时尽量取所需要的数据
加载 load
数据的加载方式一般有以下两种重要类型:
- 全量加载(Full load / Bulk load)
- 增量加载(Incremental load / Refresh load)
全量一般是第一次进行数据加载,这个过程比较长,也有种情况是业务数据存在历史全量数据不停更新的情况,这种情况无论何时都需要全量加载。还有一种情况会追溯一定的时间周期内的数据进行加载,如此业务30天之前的数据不会有再任何变化。
增加加载最为常见,一般一日加载一次,加载上一日数据,也有一周或者一月加载一次的。
加载数据是数据进入数据仓库的最后一步,加载是依赖提取和转换的,因此,加载数据是一个完整的 ETL 过程,这个过程需要大量的数据流转加工时间,而且是周期性重复的工作,所以一般由系统自动完成,执行时间为业务一个最小周期——日(实时数仓会选择更小的时间粒度,如10分钟一次),同时选择业务量小的凌晨进行。
除了增加新增加数据,加载同时伴随着对已加载数据的修改。选择何种加载类型,以及加载周期、加载内容,要看具体业务,产品经理和分析师分析需求最终确定一个最优的方案。
其他
- 一些小型的数据项目、数据报表也伴随着完整的 etl 过程
- 有时需要实时的 ETL,如推荐、金融反欺诈、反垃圾
技术方案
- OWB(Oracle Warehouse Builder)
- ODI(Oracle Data Integrator)
- Informatic PowerCenter
- AICloudETL、DataStage
- Repository Explorer
- Beeload
- DataSpider
- Kettle
- Flink
- Spark Streaming
- TASCTL
- Confluent
- Fivetran
- FlyData
- Matillion
- SnapLogic
- StreamSets
- Striim
- Alooma
- Flume
- Sqoop
- Lambda Architecture
更新时间:2020-12-05 20:12:43 标签:etl 数据 大数据
