
NumPy 的 ndarray 对象
说明
NumPy 教程 持续更新中,提供建议、纠错、催更等加作者微信: gr99123(备注:pandas教程)和关注公众号「盖若」ID: gairuo。跟作者学习,请进入 Python学习课程。欢迎关注作者出版的书籍:《深入浅出Pandas》 和 《Python之光》。

NumPy 的 ndarray 是一个(通常是固定大小)由相同类型和大小的数据组成的多维容器。数组中的维数和项数由其形状定义,形状是由 N 个非负整数组成的元组,指定每个维数的大小。数组中的项类型由单独的数据类型对象(dtype)指定,与每个 ndarray 关联。
视图 view
与 Python 中的其他容器对象一样,可以通过对数组进行索引或切片(例如,使用 N 个整数)并通过 ndarray 的方法和属性来访问和修改 ndarray 的内容。
不同的 ndarray 可以共享相同的数据,因此在一个 ndarray 中所做的更改可能在另一个中可见。也就是说,一个 ndarray 可以是另一个 ndarray 的“视图”(view),并且它所引用的数据由“基础”(base) ndarray 处理。 ndarrays 也可以是实现缓冲区或数组接口的 Python 字符串或对象所拥有的内存的视图。
案例
一个大小为 2 x 3 的二维数组,由 4 个字节的整数元素组成:
x = np.array([[1, 2, 3], [4, 5, 6]], np.int32)
type(x)
# <class 'numpy.ndarray'>
x.shape
# (2, 3)
x.dtype
# dtype('int32')
可以使用类似 Python 容器的语法为数组索引:
# 第二行第三列x的元素,即 6
x[1, 2]
# 6
切片可以产生数组的视图:
y = x[:,1]
y
# array([2, 5])
y[0] = 9 # 改变 x 中相应的元素
y
# array([9, 5])
x
'''
array([[1, 9, 3],
[4, 5, 6]])
'''
以下是一个简单的创建:
import numpy as np
# 创建15个元素的数组,形状修改成 3 行 5 列
a = np.arange(15).reshape(3, 5)
a
'''
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
'''
a.shape # 形状
# (3, 5)
a.ndim # 维数
# 2
a.dtype.name # 类型名
# 'int64'
a.itemsize # 一个数组元素的字节总长度(和类型也相关)
# 8
a.size # 大小,元素数
# 15
type(a)
# <class 'numpy.ndarray'>
b = np.array([6, 7, 8])
b
# array([6, 7, 8])
type(b)
# <class 'numpy.ndarray'>
数据结构
我们先了解一下 ndarray 结构,NumPy 支持一维到多维的数据结构:
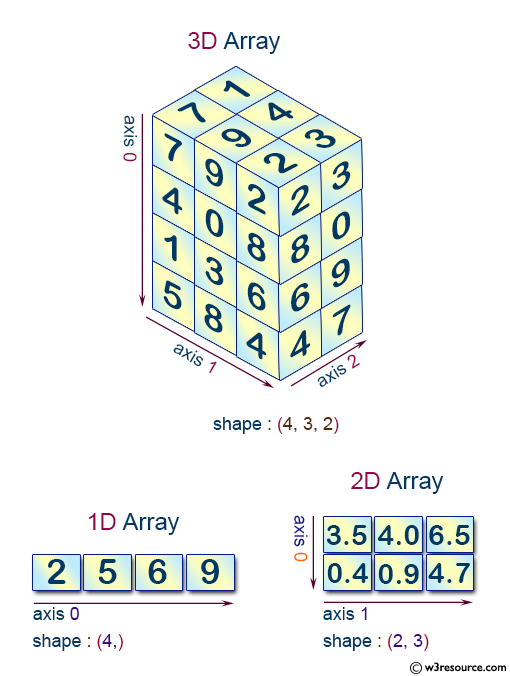
例如,在 3D 空间点 [1、2、1] 中的的坐标只有一个轴。 该轴上有 3 个元素,所以我们说它的长度为 3。在下图所示的示例中,数组有2个轴。 第一轴的长度为2,第二轴的长度为 3。
'''
[[ 1., 0., 0.],
[ 0., 1., 2.]]
'''
构造
数组对象表示固定大小项目的多维同构数组。 关联的数据类型对象描述了数组中每个元素的格式(其字节顺序,它在内存中占用多少字节,它是整数,浮点数还是其他,等等)。
语法结构如下:
numpy.ndarray(shape, dtype=float,
buffer=None, offset=0,
strides=None, order=None)
Arrays 可使用 array, zeros 或者 empty 构造(请参阅下面的另请参见部分)。 此处给出的参数指的是用于实例化数组的低级方法(low-level method ) (ndarray(…))。
构造参数
用 __new__ 方法构建的参数:
shape: tuple of ints
创建的数组的形状dtype: data-type, optional
可被解释为 numpy 数据类型的任何对象buffer: object exposing buffer interface, optional
用于用数据填充数组offset: int, optional
缓冲区中数组数据的偏移量strides: tuple of ints, optional
内存中数据的跨步(Strides)order: {‘C’, ‘F’}, optional
行优先(C 样式)或列优先(Fortran 样式)顺序
注意事项
使用 __new__ 创建数组的方式有两种:
- 如果 buffer 为 None,则仅使用 shape,dtype 和 order
- 如果 buffer 是暴露 buffer 接口的对象,则将解释所有关键字
不需要 __init__ 方法,因为数组是在 __new__ 方法之后完全初始化的。
例子
这些示例说明了低级(low-level) ndarray 构造函数。 有关构造 ndarray 的简便方法,使用:
- array:构造一个数组。
- zeros:创建一个数组,每个元素为零。
- empty:创建一个数组,但保持其分配的内存不变(即,它包含“垃圾”)。
- dtype:创建数据类型。
第一种模式, buffer 为 None:
np.ndarray(shape=(2,2), dtype=float, order='F')
'''
array([[0.0e+000, 0.0e+000], # random
[ nan, 2.5e-323]])
'''
第二种模式:
np.ndarray((2,), buffer=np.array([1,2,3]),
offset=np.int_().itemsize,
dtype=int) # offset = 1*itemsize, i.e. skip first element
# array([2, 3])
属性
ndarray 对象有以下属性:
| 属性 | 类型 | 说明 |
|---|---|---|
| T | ndarray | 数组转置 |
| data | buffer | 指向数组数据的 Python 缓冲区对象 |
| dtype | dtype object | 数组元素的数据类型 |
| flags | dict | 有关阵列内存布局的信息 |
| flat | numpy.flatiter object | 数组上的一维迭代器 |
| imag | ndarray | 数组的虚部 |
| real | ndarray | 数组的实部 |
| size | int | 数组中的元素数 |
| item | sizeint | 数组元素的长度(字节) |
| nbytes | int | 数组元素消耗的总字节数 |
| ndim | int | 数组维数 |
| shape | tuple of ints | 数组维度的元组 |
| strides | tuple of ints | 遍历数组时要在每个维度中步进的字节元组 |
| ctypes | ctypes object | 用于简化数组与 ctypes 模块的交互的对象 |
| base | ndarray | 从内存中的基本对象(如有会指向整体数组对象) |
方法
ndarray 对象有以下方法:
| 方法 | 说明 |
|---|---|
| all([axis, out, keepdims]) | 如果所有元素的布尔计算结果都为 True,则返回 True |
| any([axis, out, keepdims]) | 如果元素的任何元素的布尔值为 True,则返回 True,否则为 False |
| argmax([axis, out]) | 沿给定轴返回最大值的索引 |
| argmin([axis, out]) | 沿给定轴返回最小值的索引 |
| argpartition(kth[, axis, kind, order]) | 返回将对此数组进行分区的索引 |
| argsort([axis, kind, order]) | 返回将对此数组进行排序的索引 |
| astype(dtype[, order, casting, subok, copy]) | 强制转换为指定类型后返回数组的副本 |
| byteswap([inplace]) | 交换数组元素的字节 |
| choose(choices[, out, mode]) | 使用索引数组从一组选项构造新数组 |
| clip([min, max, out]) | 返回值限制为 [min,max] 的数组 |
| compress(condition[, axis, out]) | 沿给定轴返回此数组的选定切片 |
| conj() | 复共轭所有元素 |
| conjugate() | 按元素返回复共轭 |
| copy([order]) | 返回数组的副本 |
| cumprod([axis, dtype, out]) | 返回元素沿给定轴的累积 |
| cumsum([axis, dtype, out]) | 返回给定轴上元素的累加 |
| diagonal([offset, axis1, axis2]) | 返回指定的对角线 |
| dot(b[, out]) | 两个数组的点积 |
| dump(file) | 将数组的 pickle 转储到指定的文件。 |
| dumps() | 以字符串形式返回数组的 pickle |
| fill(value) | 用标量值填充数组 |
| flatten([order]) | 返回折叠为一维的数组的副本 |
| getfield(dtype[, offset]) | 以特定类型返回给定数组的字段 |
| item(*args) | 将数组的元素复制到标准 Python 标量并返回它 |
| itemset(*args) | 将标量插入数组(如果可能,标量将被转换为数组的数据类型) |
| max([axis, out, keepdims, initial, where]) | 沿给定轴返回最大值 |
| mean([axis, dtype, out, keepdims]) | 返回给定轴上数组元素的平均值 |
| min([axis, out, keepdims, initial, where]) | 沿给定轴返回最小值 |
| newbyteorder([new_order]) | 返回以不同字节顺序查看相同数据的数组 |
| nonzero() | 返回非零元素的索引 |
| partition(kth[, axis, kind, order]) | 重新排列数组中的元素,使第k个位置的元素的值位于排序数组中的位置 |
| prod([axis, dtype, out, keepdims, initial, …]) | 返回数组元素在给定轴上的乘积 |
| ptp([axis, out, keepdims]) | 沿给定轴的峰间(最大-最小)值 |
| put(indices, values[, mode]) | 设置 a.flat[n]=索引中所有 n 的值 [n] |
| ravel([order]) | 返回展平数组 |
| repeat(repeats[, axis]) | 重复数组的元素 |
| reshape(shape[, order]) | 返回包含具有新形状的相同数据的数组 |
| resize(new_shape[, refcheck]) | 更改阵列的形状和大小 |
| round([decimals, out]) | 返回 a,每个元素四舍五入到给定的小数位数 |
| searchsorted(v[, side, sorter]) | 找到v元素应该插入a中以保持顺序的索引 |
| setfield(val, dtype[, offset]) | 将值放入由数据类型定义的字段中的指定位置 |
| setflags([write, align, uic]) | 分别设置数组标志 WRITEABLE、ALIGNED、(WRITEBACKIFCOPY和UPDATEIFCOPY) |
| sort([axis, kind, order]) | 对数组进行排序并替换 |
| squeeze([axis]) | 从形状中删除一维条目 |
| std([axis, dtype, out, ddof, keepdims]) | 返回数组元素沿给定轴的标准偏差 |
| sum([axis, dtype, out, keepdims, initial, where]) | 返回给定轴上数组元素的总和 |
| swapaxes(axis1, axis2) | 返回交换了axis1和axis2的数组视图 |
| take(indices[, axis, out, mode]) | 返回由给定索引处的元素组成的数组 |
| tobytes([order]) | 构造包含数组中原始数据字节的 Python 字节 |
| tofile(fid[, sep, format]) | 将数组作为文本或二进制(默认)写入文件 |
| tolist() | 以Python标量的a.ndim-levels深度嵌套列表的形式返回数组 |
| tostring([order]) | tobytes的兼容性别名,具有完全相同的行为 |
| trace([offset, axis1, axis2, dtype, out]) | 返回沿数组对角线的和 |
| transpose(*axes) | 返回轴已转置的数组视图 |
| var([axis, dtype, out, ddof, keepdims]) | 返回数组元素沿给定轴的方差 |
| view([dtype][, type]) | 具有相同数据的数组的新视图 |
这些方法的使用我们后边都会有相应的介绍。
参考
- https://numpy.org/doc/stable/reference/generated/numpy.ndarray.html
更新时间:2021-01-08 08:26:13 标签:numpy array
