
pandas eval() 表达式计算
看过来
《pandas 教程》 持续更新中,提供建议、纠错、催更等加作者微信: gr99123(备注:pandas教程)和关注公众号「盖若」ID: gairuo。跟作者学习,请进入 Python学习课程。欢迎关注作者出版的书籍:《深入浅出Pandas》 和 《Python之光》。

pandas 提供了通过 eval() 进行表达式计算的功能,可以写出简洁、易读的代码。pandas 的顶级方法 eval 可以使用各种后端引擎将 Python 表达式作为字符串进行求值。DataFrame 也有 eval 方法,用于对当前数据进行计算。
pandas.eval
语法为:
pd.eval(expr: 'str | BinOp',
parser: 'str' = 'pandas',
engine: 'str | None' = None,
truediv=<no_default>,
local_dict=None,
global_dict=None,
resolvers=(), level=0,
target=None,
inplace=False)
参数详解:
- expr : str,要计算的表达式此字符串,不能包含任何 Python 语句(statements),仅包含 Python 表达式(expressions)。
- parser : {'pandas', 'python'}, 默认 'pandas',用于从表达式构造语法树的解析器。默认 'pandas' 与标准 Python 代码略有不同, Python 解析器保留严格的 python 语义。
- engine : {'python', 'numexpr'}, 默认 'numexpr',用于计算表达式的引擎。支持的引擎是:
- None : 尝试使用
numexpr,失败后回退到python 'numexpr': 此默认引擎使用 numexpr 用于复杂表达式中的大加速大 DataFrame'python': 就像 Python 的 eval 一样执行操作,一般不太有用。- pandas 将来可能会有更多的后端引擎可用。
- None : 尝试使用
- truediv : bool, 可选,是否使用真除法,在 pandas 1.0.0 中移除(不要再使用)
- local_dict : dict 或者 None, 可选,局部变量字典,默认情况下取自 locals()
- global_dict : dict 或者 None, 可选,全局变量字典,默认情况下取自 globals()
- resolvers : list of dict-like(映射列表) 或者 None, 可选,方法解析器。实现
__getitem__特殊方法的对象列表,这些对象你可以注入其他命名空间用于变量查找。 比如,~DataFrame.query的方法注入DataFrame.index和DataFrame.columns引入各自的变量到~pandas.DataFrame的实例属性 - level : int, 可选。要遍历并添加到当前堆栈数据框的先前堆栈帧数范围,大多数用户不需要更改此参数
- target : object, 可选, 默认为 None,这是赋值的目标对象。它是在有需要时使用的表达式中的变量赋值,如果这样,那么“target”必须支持使用字符串键分配项目,如果正在创建副本返回时,它还必须支持
.copy() - inplace : bool, 默认 False,如果提供了'target',并且表达式变异为'target',则在原地修改'target'。否则,返回带有变异的数据
返回:
- ndarray, numeric scalar, DataFrame, Series, 或者 None
- 计算给定代码的完成值,如果
inplace=True,则为 None
注:算术%运算中涉及的任何对象的数据类型都递归转换为 float64。
异常引发:
- ValueError:在许多情况下,可能会出现此类错误:
target=None,但是表达式是多行的。- 表达式是多行的,但并非所有表达式都具有项赋值。
一个例子是:
a = b + 1
a + 2
在这里,在不同的行上有表达式,使其成为多行,但是最后一行没有为 'a+2' 的输出分配变量。 inplace=True,但表达式缺少项赋值。- 提供了项分配,但“target”不支持字符串项分配
- 提供了项分配,且
inplace=False,但 target 不支持.copy()方法
示例:
df = pd.DataFrame({"animal": ["dog", "pig"], "age": [10, 20]})
df
'''
animal age
0 dog 10
1 pig 20
'''
# 我们可以使用 pd.eval 添加一个新列:
pd.eval("double_age = df.age * 2", target=df)
'''
animal age double_age
0 dog 10 20
1 pig 20 40
'''
DataFrame.eval
DataFrame.eval 描述对 DataFrame 列的操作的字符串进行计算。它仅对列进行操作,而不对特定行或元素进行操作。它允许 eval 运行任意代码,如果您将用户输入传递给此函数,这会使你容易受到代码注入的攻击,因此这个方法只能由你控制,不要开发给外部调用。
语法为:
DataFrame.eval(expr, inplace=False, **kwargs)
参数:
- expr : str,要计算的表达式字符串
- inplace : bool, 默认 False,如果表达式包含赋值,则是否执行操作替换并改变现有数据帧,否则返回一个新的数据帧
**kwargs:传入pd.eval的参数
返回:
- 计算结果,ndarray, scalar, pandas object, 或者 None
- 如果
inplace=True则为 None
讲解:
pandas.eval() 它任何有效的表达式也是对 DataFrame.eval() 有效的,还有一个好处,就是你操作时不必将 DataFrame 的名称作为您期望的列的前缀,仅需要直接写列名称即可。此外,还可以在表达式中执行列赋值,这允许给定一个计算列公式以及新列名就能完成,赋值目标可以是新列名或现有列名(现列名会覆盖),这些操作要求列名必须是有效的 Python 标识符。inplace 关键字为 True 可对原始 DataFrame 执行此赋值,返回包含新列的副本。如:
df = pd.DataFrame(dict(a=range(5), b=range(5, 10)))
df.eval("c = a + b", inplace=True)
df.eval("d = a + b + c", inplace=True)
df.eval("a = 1", inplace=True)
df
'''
a b c d
0 1 5 5 10
1 1 6 7 14
2 1 7 9 18
3 1 8 11 22
'''
当 inplace 设置为 False(默认值)时,将返回具有新列或修改列的 DataFrame 的副本,并且原始帧不变。
df
'''
a b c d
0 1 5 5 10
1 1 6 7 14
2 1 7 9 18
3 1 8 11 22
4 1 9 13 26
'''
# 默认参数取值
df.eval("e = a - c", inplace=False)
'''
a b c d e
0 1 5 5 10 -4
1 1 6 7 14 -6
2 1 7 9 18 -8
3 1 8 11 22 -10
4 1 9 13 26 -12
'''
# 原 DataFrame 没有变化
df
'''
a b c d
0 1 5 5 10
1 1 6 7 14
2 1 7 9 18
3 1 8 11 22
4 1 9 13 26
'''
为了方便起见,可以使用多行字符串执行多个赋值。
df.eval(
"""
c = a + b
d = a + b + c
a = 1""",
inplace=False,
)
'''
a b c d
0 1 5 6 12
1 1 6 7 14
2 1 7 8 16
3 1 8 9 18
4 1 9 10 20
'''
# 相当于以下标准 Python 代码
df = pd.DataFrame(dict(a=range(5), b=range(5, 10)))
df["c"] = df["a"] + df["b"]
df["d"] = df["a"] + df["b"] + df["c"]
df["a"] = 1
df. query 查询方法也有一个 inplace 关键字,用于确定查询是否修改原始 DataFrame。
案例:
df = pd.DataFrame({'A': range(1, 6), 'B': range(10, 0, -2)})
df
'''
A B
0 1 10
1 2 8
2 3 6
3 4 4
4 5 2
'''
df.eval('A + B')
'''
0 11
1 10
2 9
3 8
4 7
dtype: int64
'''
# 虽然默认情况下未修改原始数据帧,但允许赋值
df.eval('C = A + B')
'''
A B C
0 1 10 11
1 2 8 10
2 3 6 9
3 4 4 8
4 5 2 7
'''
df
'''
A B
0 1 10
1 2 8
2 3 6
3 4 4
4 5 2
'''
# 用 inplace=True 修改原始的 DataFrame
df.eval('C = A + B', inplace=True)
df
'''
A B C
0 1 10 11
1 2 8 10
2 3 6 9
3 4 4 8
4 5 2 7
'''
# 可以使用多行表达式将多个列指定给它
df.eval(
'''
C = A + B
D = A - B
'''
)
'''
A B C D
0 1 10 11 -9
1 2 8 10 -6
2 3 6 9 -3
3 4 4 8 0
4 5 2 7 3
'''
支持的语法
支持以下算术运算:+, -, *,/, **, %, //(仅限 python 引擎)以及以下布尔运算: | (or), & (and), 和 ~ (not)。此外,“pandas”解析器允许使用 and、or 和 not,其语义与相应的位运算符不同。
pandas.eval() 支持这些操作:
- 算术运算,除左移 (<<) 和右移 (>>) 操作, 如
df + 2 * pi / s ** 4 % 42 - the_golden_ratio - 比较操作,包括链式比较,如
2 < df < df2 - 布尔运算,如
df < df2 and df3 < df4 or not df_bool - 列表和元组字面量, 如
[1, 2] or (1, 2) - 属性访问,如
df.a - 下标表达式,如
df[0] - 单变量评价计值,如
pd.eval("df")(这不是很有用) - 数学函数,有 sin, cos, exp, log, expm1, log1p, sqrt, sinh, cosh, tanh, arcsin, arccos, arctan, arccosh, arcsinh, arctanh, abs, arctan2 和 log10
不允许使用此 Python 语法:
- 表达式
- 函数调用(非以上说的数学函数)
- is/is not 操作
- if 表达式
- lambda 表达式
- list/set/dict 解析式
- dict 和 set 字面量表达式
- yield 表达式
- 生成器表达式
- 仅由标量值组成的布尔表达式
- 语句
- 不允许使用简单或复合语句,这包括 for、while 和 if
局部变量 Local variables
必须通过在名称前面放置 @ 字符来显式引用要在表达式中使用的任何局部变量。例如:
df = pd.DataFrame(np.random.randn(5, 2), columns=list("ab"))
newcol = np.random.randn(len(df))
# 变量 newcol 参考计算
df.eval("b + @newcol")
'''
0 -0.173926
1 2.493083
2 -0.881831
3 -0.691045
4 1.334703
dtype: float64
'''
df.query("b < @newcol")
'''
a b
0 0.863987 -0.115998
2 -2.621419 -1.297879
'''
如果不在局部变量前面加 @,pandas 将引发异常,告诉您该变量未定义。当使用数据帧时。DataFrame.eval() 和 DataFrame.query() 允许您在表达式中具有相同名称的局部变量和DataFrame 列。
a = np.random.randn()
df.query("@a < a")
'''
a b
0 0.863987 -0.115998
'''
# 与上边的表达式相同
df.loc[a < df["a"]]
'''
a b
0 0.863987 -0.115998
'''
在使用 pandas.eval() 时,您根本不能使用 @ 前缀,因为它没有在该上下文中定义。如果您尝试在 pandas 顶级 eval 使用 @,pandas 会报错让您知道这一点。例如:
a, b = 1, 2
pd.eval("@a + b")
'''
Traceback (most recent call last):
...
SyntaxError: The '@' prefix is not allowed in top-level eval calls.
please refer to your variables by name without the '@' prefix.
'''
在本例中,您应该像在标准Python中一样简单地引用变量:
pd.eval("a + b")
# 3
以下案例是用 pd.to_datetime 对列进行类型转换,可以对比一下:
df = pd.DataFrame({'A': ['20220101', '20220102'], 'B': [1, 2]})
df
'''
A B
0 20220101 1
1 20220102 2
'''
# 变量需要加 @
df.eval('A= @pd.to_datetime(A)')
'''
A B
0 2022-01-01 1
1 2022-01-02 2
'''
# 变量不需要加 @
pd.eval("pd.to_datetime(df.A)")
'''
0 2022-01-01
1 2022-01-02
Name: A, dtype: datetime64[ns]
'''
pd.eval 解析器 parsers
有两个不同的解析器和两个不同的引擎可以用作后端支持。默认的 pandas 解析器允许使用更直观的语法来表示类似查询的操作(比较、连接和析取)。特别是,& 和 | 运算符的优先级等于相应布尔运算和或的优先级。
例如,上面的连词可以不用括号书写。或者,您可以使用 “python” 解析器强制执行严格的 Python 语义。
expr = "(df1 > 0) & (df2 > 0) & (df3 > 0) & (df4 > 0)"
x = pd.eval(expr, parser="python")
expr_no_parens = "df1 > 0 & df2 > 0 & df3 > 0 & df4 > 0"
y = pd.eval(expr_no_parens, parser="pandas")
np.all(x == y)
# True
同一表达式可以与单词 and 一起使用 “and”:
expr = "(df1 > 0) & (df2 > 0) & (df3 > 0) & (df4 > 0)"
x = pd.eval(expr, parser="python")
expr_with_ands = "df1 > 0 and df2 > 0 and df3 > 0 and df4 > 0"
y = pd.eval(expr_with_ands, parser="pandas")
np.all(x == y)
# True
这里的 and 和 or 运算符与普通 Python 中的 and 和 or 运算符具有相同的优先级。
pd.eval() 的后端 backends
还有一个选项可以使 eval() 的操作与普通 Python 相同。使用 “python” 引擎通常没有用处,除了针对它测试其他评估引擎。使用 eval() 和 engine='python' 不会获得任何性能好处,实际上可能会导致性能下降。
你可以通过 pandas.eval() 看到这一点。使用“python”引擎执行 pandas.eval() 它比在 Python 中计算同一个表达式要慢一点(不是很多):
%timeit df1 + df2 + df3 + df4
8.91 ms +- 100 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
%timeit pd.eval("df1 + df2 + df3 + df4", engine="python")
10.1 ms +- 34.5 us per loop (mean +- std. dev. of 7 runs, 100 loops each)
pd.eval() 性能
eval() 用于加速某些类型的操作。特别是,那些涉及具有大型 DataFrame/Series 对象的复杂表达式的操作应该可以看到显著的性能优势。
有两点优势:
- 计算时间
- 内存消耗
- 写法简洁
传统方法在较小的 array 上更快一些,使用 eval/query 主要是节省内存以及有时他们具有更简洁的语法形式。
这是一张显示 pandas 运行时间的图,eval() 作为计算中涉及的帧大小的函数。这两条线是两个不同的引擎。
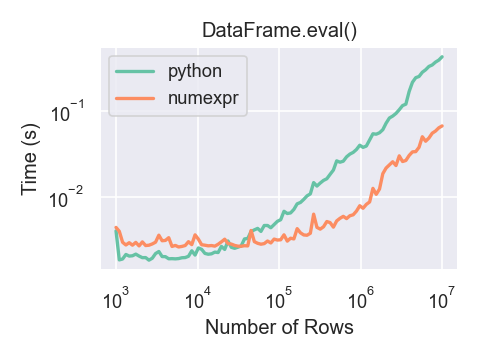
使用常规 Python 对较小对象(约15k-20k行)的操作速度更快:

此绘图是使用 DataFrame 创建的,DataFrame 有 3 列,每列包含使用 numpy 生成的浮点值,numpy.random.randn()。
应用说明
使用 eval() 而不是普通 Python 表达式求值有两个要点:
1)大型数据帧对象的求值效率更高
2)大型算术和布尔表达式由底层引擎一次性求值(默认情况下,使用 numexpr 进行求值)
对于简单表达式或涉及小数据帧的表达式,不应使用 eval()。事实上,对于较小的表达式/对象,eval() 比普通的一般 Python 慢很多数量级。一个很好的经验法则是,只有当数据帧的行数超过10000 行时,才使用 eval()。
eval() 支持引擎支持的所有算术表达式,以及一些仅在 pandas 中可用的扩展。数据越大,表达式越复杂,使用 eval 可以看到的加速效果就越高。
numexpr
eval() 可以安装三方库 numexpr,它用于加速某些数值运算,使用多核以及智能分块和缓存来实现较大的加速。如果已安装,则必须为 2.7.0 或更高版本。
numexpr 库通过在CPU 的 cache 中逐元素的计算,实现无中间内存开销,只需要传入一个 Numpy-Style的表达式字符串。
import numexpr
mask_numexpr = numexpr.evaluate('(x > 0.5) & (y < 0.5)')
其他
一些其他事项:
适用对象
eval() 支持的对象包含:
- pandas.DataFrame.eval
- pandas.eval
参考
- https://pandas.pydata.org/docs/reference/api/pandas.eval.html
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.eval.html
- https://pandas.pydata.org/docs/user_guide/enhancingperf.html#expression-evaluation-via-eval
- https://github.com/pydata/numexpr
- https://zhuanlan.zhihu.com/p/74511940
相关内容
- pandas习题 102:eval() 添加筛选数据 2025-08-16 17:09:35
- pandas 根据入职日期和工资月份计算司龄 2024-11-07 17:28:35
- pandas 将持续时间列转换为开始和结束列 2024-08-10 17:56:02
- pandas习题 039:时间两列间隔秒数 2024-08-10 12:29:36
- pandas 解析开始结束年份和最大间隔 2023-10-25 10:30:10
- pandas 标记连续3个1的序号 2023-04-02 14:11:38
- pandas 将带有万和亿的数字转为整型 2022-11-22 18:39:41
更新时间:2023-05-16 17:03:28 标签:pandas eval 表达式
